
The annual data (FUNDA) is easy to deal with; we just need to apply the following conditions:
indfmt=="INDL" & datafmt=="STD" & popsrc=="D" & consol=="C"
If we have converted FUNDA to Stata format, the uniqueness of GVKEY–DATADATE can be verified using the following Stata command:
duplicates report gvkey datadate if indfmt=="INDL" & datafmt=="STD" & popsrc=="D" & consol=="C"
This command should return “no duplicates”.
The quarterly data (FUNDQ) is a bit more complicated. First of all, applying the same conditions won’t work. In fact, 99.7% observations in FUNDQ already satisfy these conditions. However, duplicate GVKEY–DATADATEs still exist in FUNDQ. The root cause of these duplicates is a firm changing its fiscal year-end. I use the following example for illustration:
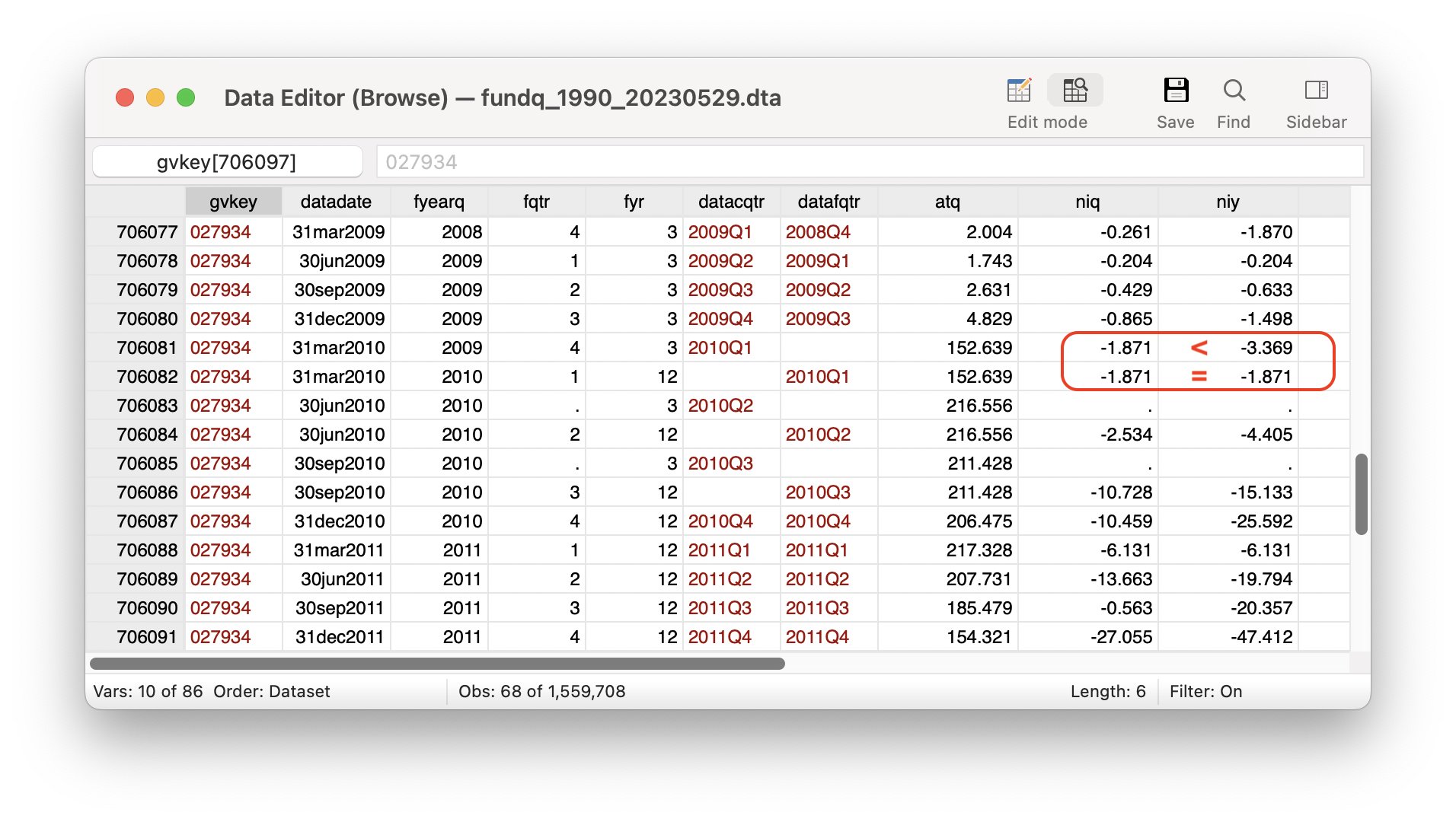
Variable definition: FYEARQ – fiscal year; FQTR – fiscal quarter; FYR – fiscal year-end month; DATACQTR – calendar quarter; DATAFQTR – fiscal quarter; ATQ – total assets; NIQ – quarterly net income; NIY – year-to-date net income.
In this example, duplicates exist for three DATADATEs: 2010-03-31, 2010-06-30, and 2010-09-30. The data suggest that on March 31, 2010, the firm changed its fiscal year-end from March 31 to December 31 (i.e., FYR changed from 3 to 12). As a result, 2010-03-31 appeared twice in FUNDQ, once as fiscal 2009Q4 (based on the old fiscal year-end) and once as 2010Q1 (based on the new fiscal year-end). FUNDQ also reports additional duplicates for the subsequent two quarters (I don’t know why). Additionally, if we compare NIQ and NIY as highlighted in the red rectangle, the observation for fiscal 2009Q4 indicates NIY > NIQ, which makes sense as NIY is a four-quarter sum and NIQ is single-quarter net income. In contrast, the observation for fiscal 2010Q1 indicates NIQ = NIY as both are single-quarter net income in this case.
So, what’s the best strategy to remove duplicate GVKEY–DATADATEs?
Before we answer this question, let’s take a closer look at duplicate GVKEY–DATADATEs in FUNDQ, which reveals that 99.8% of GVKEY–DATADATEs in FUNDQ are unique as of December 5, 2107. This suggests that no matter how we deal with duplicates, even simply delete all of them, our results probably won’t change in a noticeable way.
That said, if we want to remove duplicates more carefully, COMPUSTAT provides the following clue:
In the definition of DATAFQTR, COMPUSTAT notes that,
Note: Companies that undergo a fiscal-year change may have multiple records with the same datadate. Compustat delivers those multiple records with the same datadate but each record relates to a different fiscal year-end period.
Rule: Select records from the co_idesind data group where datafqtr is not null, to view as fiscal data.
Unfortunately, I find that the suggested rule is not the best strategy because COMPUSTAT seems to set DATAFQTR as missing or non-missing inconsistently. In my opinion, the best strategy is to retain the GVKEY–DATADATE that reflects the most recent change of fiscal year-end. This means, in the above example, we should delete the following observations:
-
DATADATE= 2010-03-31 andFYR= 3DATADATE= 2010-06-30 andFYR= 3DATADATE= 2010-09-30 andFYR= 3
Suppose we have converted FUNDQ to Stata format. The following Stata code will implement the above strategy. The code will also fill in missing DATAFQTR and remove duplicate GVKEY–DATAFQTR, which will later allow us to use the tsset command and perform lag and change calculations in Stata, e.g., to get beginning-of-quarter total assets or calculate quarterly changes in sales. Stata really shines in lag and change calculations for panel data—a superb advantage over SAS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
use fundq, clear // Keep necessary variables only for testing keep gvkey datadate fyearq fqtr fyr datacqtr datafqtr atq saleq // Generate unique ID for stable sorting (keep original order when tied) gen _id = _n // Check if gvkey, datadate, and fyr are missing - NO assert !missing(gvkey, datadate, fyr) // manually clean up missing values // Convert datacqtr and datafqtr to datatime gen _datacqtr = quarterly(datacqtr, "YQ") gen _datafqtr = quarterly(datafqtr, "YQ") format _datacqtr _datafqtr %tq drop datacqtr datafqtr rename _datacqtr datacqtr rename _datafqtr datafqtr order datacqtr datafqtr, after(fyr) // Check if datafqtr is a simple combination of fyearq and fqtr - YES gen _datafqtr = yq(fyearq, fqtr) gen _diff = _datafqtr - datafqtr sum _diff, detail drop _datafqtr _diff // Check if datacqtr is simply based on datadate - NO. Jan, Apr, Jul and Oct will be coded as the previous quarter gen _datacqtr = qofd(datadate) format _datacqtr %tq gen _diff = datacqtr - _datacqtr sum _diff, detail drop _datacqtr _diff // Remove duplicate gvkey-datadate duplicates tag gvkey datadate, ge(dup) tab dup assert dup == 1 | dup == 0 // if false, manually clean up dup >= 2 sort gvkey datadate _id by gvkey: egen is_fyr_changed = max(dup) tab is_fyr_changed by gvkey: egen max_dup_gvkey_datadate = total(dup) sum max_dup_gvkey_datadate, detail local iter = r(max) - 2 gen last=1 if dup==1 & dup[_n+1]==0 replace last=0 if dup==1 & last==. by gvkey: gen newfyr=fyr[_n+1] if last==1 by gvkey: replace newfyr=newfyr[_n+1] if last==0 & last[_n+1]==1 forvalues i = 1/`iter' { by gvkey: replace newfyr=newfyr[_n+1] if last==0 & last[_n+1]==0 } drop if dup==1 & fyr!=newfyr duplicates report gvkey datadate // no duplicates drop dup is_fyr_changed max_dup_gvkey_datadate last newfyr save fundq_no_dup_gvkey_datadate, replace // Fill in missing datafqtr * generate next fiscal year end date gen _fyearend_1 = lastdayofmonth(mdy(fyr, 1, year(datadate))) gen _fyearend_2 = lastdayofmonth(mdy(fyr, 1, year(datadate)+1)) gen fyearend = _fyearend_1 if datadate <= _fyearend_1 replace fyearend = _fyearend_2 if datadate > _fyearend_1 format fyearend %td order fyearend, after(datafqtr) * generate _datafqtr based on Compustat Manual gen _month_diff = mofd(fyearend) - mofd(datadate) gen _fyearq = year(fyearend) replace _fyearq = year(fyearend) - 1 if month(fyearend) <= 5 gen _datafqtr = yq(_fyearq, 1) if _month_diff == 9 replace _datafqtr = yq(_fyearq, 2) if _month_diff == 6 replace _datafqtr = yq(_fyearq, 3) if _month_diff == 3 replace _datafqtr = yq(_fyearq, 4) if _month_diff == 0 format _datafqtr %tq * check if datafqtr is correct if datafqtr is not missing - YES gen _diff = datafqtr - _datafqtr if datafqtr!=. sum _diff, detail drop _diff * replace missing datafqtr with computed _datafqtr replace datafqtr = _datafqtr if datafqtr == . // Remove duplicate gvkey-datafqtr duplicates tag gvkey datafqtr, ge(dup) tab dup by gvkey: egen has_dup=max(dup) tab has_dup gsort - _id duplicates drop gvkey datafqtr, force sort _id duplicates report gvkey datafqtr // no duplicates drop dup has_dup _* replace fqtr = quarter(dofq(datafqtr)) if fqtr==. assert !missing(gvkey, datadate, fyr, datafqtr, fqtr) // manually investigate missing values save fundq_no_dup_gvkey_datafqtr, replace |
Please note: I also agree with one of the readers’ comments that “(how to remove duplicates) depends on what you need”. For example, in one of my projects, I want to examine three-day CAR around earnings announcement date (RDQ) and use total assets as the deflator in my regression. As a result, when duplicate GVKEY–DATADATEs exist, the one with non-missing RDQ and ATQ will be preferred if I want to retain as many observations as possible.
Hi, Kai, I think it depends on what you need, it could be either calendar quarter or fiscal quarter. I usually try to collect the information for each calendar quarter, in that case, I only keep the recent convention for the duplicated observations.
Hi Yanlei, thanks for your comments. I agree—it depends on the need. Many ways to do this, and perhaps it doesn’t matter which way to use since duplicate observations are so tiny percentage. But I do find Compustat hasn’t created
datacqtranddatafqtrin a consistent way (missing or non-missing), which makes the two variables unreliable. But it would be fine if you create the two quarter variables by yourself fromdatadate,fyearq, andfqtr. Another thought is fiscal quarter cannot be ignored, particularly if you use year-to-date variables. For example, NIQ and NIY are quarterly and year-to-date net income. If you use NIY to calculate quarterly net income, fiscal Q1 NIY should equal NIQ; but for other quarters, you need take difference between NIY[t] and NIY[t-1] for quarter [t] number. Thus, fiscal quarter indicates the need to compute the difference or not. This may not be a problem since Compustat provides both NIQ and NIY and you can simply use NIQ. But for other variables like cash flows, Compustat only provides year-to-date data. In that case, fiscal quarter needs to be considered.Hi Kai. I found that there is a difference in the number of observations every download from Compustat in the same period. For example, I downloaded 10 variables from Compustat in 1993-2016 with 380,0000 observations. Then I need another variable and download this variable separately from Compustat. However, I found that the number of observations are different in 2 files regardless of the same period. After that, I merge two files. After merging, some observations are not matched in 2 files. Can you help me explain why the number of observations in 2 files are different for the same period in Compustat?
This happened because the data vendor constantly updated Compustat and they might update past data when new information came in. The best strategy in empirical work is to download a snapshot of full Compustat and use that snapshot throughout.
In the spirit of having robust empirical work, it should not matter.
Hi, Kai. Thanks for sharing! I am wondering whether you notice that there are firms report financial data in Canadian dollars in COMPUSTAT (“curcd” = CAD). However, I barely saw papers mentioned that how to deal with it. What’s your opinion? Should we exclude the firms or exchange them to US dollars?
Some researchers will apply additional filter: retain firms incorporated in USA (Compustat contains a variable for that). This should roughly solve your question. Of course, if currency matters, you should use proper exchange rate if you want to retain Canadian firms as well. But because most variables we calculate are ratios (e.g., scaled by total assets), currency may not matter anyway.
Hi Kai, the WRDS rule mentioned above mentions datacqtr (calendar quarter) and not datafqtr, if I am not mistaken. If all that you are interested in is exact duplicates, then the above method for quarterly data is fine. But there will still remain an issue of overlapping months, when firms change month of financial year end. In the strict sense, this too could be treated as a duplicate observation. For example, if in the year 2002 a firm changed financial year end from May to June, Compustat will capture both in subsequent rows. The May observation and the June observation will have 2 overlapping months (May and April). To remove all such cases of overlap, you will need to consider the observations where the datacqtr is a null/ blank. Doing so will subsume all cases of exactly duplicate observations as well. But just using the ‘datacqtr is a null’ criteria will not help uniquely identify exact duplicates. This is what I found out based on a subset of data, though I might have missed some additional possibilities.
Thanks for your comments. I think COMPUSTAT rule is saying “retain observations with non-missing
datafqtr(i.e., fiscal quarter instead of calendar quarter). However, even if COMPUSTAT set a rule on how to create datafqtr and datacqtr), I find they hasn’t applied that rule in a consistent way. That’s why I think their tip is not reliable. I don’t think overlapping months in your example is a problem—as long as the observation reports a quarterly number (three-month), I’m fine with it. I recently updated the strategy to remove duplicates, which may provide new perspectives. Thanks again for your inputs.Thank you for you post! I was wondering what is the date variable in quarterly compustat if I want to merge it to monthly CRSP? “datadate” or “datacqtr”?
datadate
Hi chen. I always benefit from reading your posts. They are informative and practical. One simple question: when i extract the annual data from Compustata (Stata), I will get more 500,000+ observations for the period from 1950 to 2010. Even if I restrict my sample firms to those that I could identifiy them through CCM table, the firm-years are about 300,000. However, manny papers use much smaller sample size. I would like to know what restrictions you may impose on the sample selection?
Very useful post Kai, thanks!
It would be even more helpful to extend it up to the point where you actually tsset the dataset in quarters. It turns out that you need to generate a quarterly date from datadate and this new variable, used to tsset, also has duplicates. How would you manage this situation / optimally drop these duplicates?
Hi Kai,
I recently downloaded it and found that for annual data, the condition “indfmt==”INDL” & datafmt==”STD” & popsrc==”D” & consol==”C”” does not prevent duplicates now. It used to work, but now there are still several duplicates. When I set the CURCD == USD, there are no duplicates any more. But the sample of course is smaller.
Hi Kai,
Thanks for your post.
I still have one question in terms of repeated GVKEY-FYEAR. Since my research needs to use the GVKEY and FYEAR to merge with another dataset. Even though I have the unique GVKEY-DATADATE, I could identify repeated GVKEY-FYEAR. Can I keep the GVKEY-FYEAR with the most recent DATADATE? Many thanks.
Hi Kai,
Thanks for your post.
I don’t know if my understanding is wrong. But the codes ‘by gvkey: ge newfyr=fyr[_n+1] if last==1’ will drop the obs with duplicates happen in the final year of each gvkey. As the fyr[_n+1] will be none (.). In this case, newfyr == .
Hi Kai, thank you very much for this post. Could you please let me know what the “FS” and “INDL” means in Compustat? I searched for it but found no answer
From Computstat data dictionary: This code indicates whether a company reports in a Financial Services or Industrial format. Industry Format (INDFMT) describes the general industry presentation for the associated data record. This allows you to view a company (such as Aetna) as an industrial company or as a financial serves company with all the associated data items, thus making it easier to dissect a company.